What I Learned Trying to Teach AI the 5 Why
A current-state note on AI, RootCoach, 5 Why analysis, and why stronger models still need disciplined problem-solving logic.
As some readers are aware, I have been experimenting quite a bit with large language models, problem solving, and AI-assisted coaching tools.
Last year I joined an LEI webinar on Lean and AI where I demonstrated several problem-solving tools I had built using agentic programming methods. One was RootCoach, a 5 Why coaching application that helps users build and critique causal chains. The webinar is available here: Lean AI Webinar: A New Way to Learn, Practice, and Apply Lean Thinking.
As I mentioned there, I was skeptical about the early models. I initially set out to prove what they could not do: reason through root cause analysis, especially a basic 5 Why. In the beginning, I was mostly right. The models were fluent, entertaining, and often wrong.
But the models kept improving, and RootCoach changed my mind. With the right structure, the model could produce reasonable 5 Whys and, more importantly, critique the thinking like an actual coach would.
That work later caught the attention of Jeff Liker, who was writing a forthcoming book on technology and Toyota. Since this field changes every six months, I thought it would be useful to lay out the fuller path I took studying the models and what I realized they could and could not do. This is not a prediction piece. It is a timestamp — my current-state note as of May 2026.
My Initial Skepticism
Two or three years ago, around the first public wave of ChatGPT-style tools, I was experimenting with the models partly because I wanted to learn Python and TypeScript better. I was curious, but I was also skeptical.
The early models hallucinated, jumped to conclusions, and filled in missing facts with plausible nonsense. My first serious test was root cause analysis. Could a model perform or critique a basic 5 Why staircase? 5 Why is a simple root-cause technique: ask why a problem occurred, then keep drilling down the causal chain until you reach a cause you can verify and act on.
The results were hilariously bad. The model would drill down two or three levels and then go sideways. It would jump into solutions, blame training or procedures, and hypothesize root causes that were not verifiable. In other words, it behaved like many untrained people do in operations.
That was the funny part. The AI was bad at 5 Why in a very human way.
The Straw-Man Example Problem
A deliberately weak 5 Why is useful for teaching beginners, but it can become a straw man if people mistake it for the real test of current AI capability.
For example: machines keep breaking down because they are old, they were bought long ago, the company has used them for years, management did not want to buy new ones, and new machines cost too much money.
This feels like an explanation, but it is not a real causal analysis. “Old” is a descriptor, not a mechanism. “Cost too much money” may be a business constraint, but it does not explain which component failed, how it failed, under what condition, and how the failure can be verified.
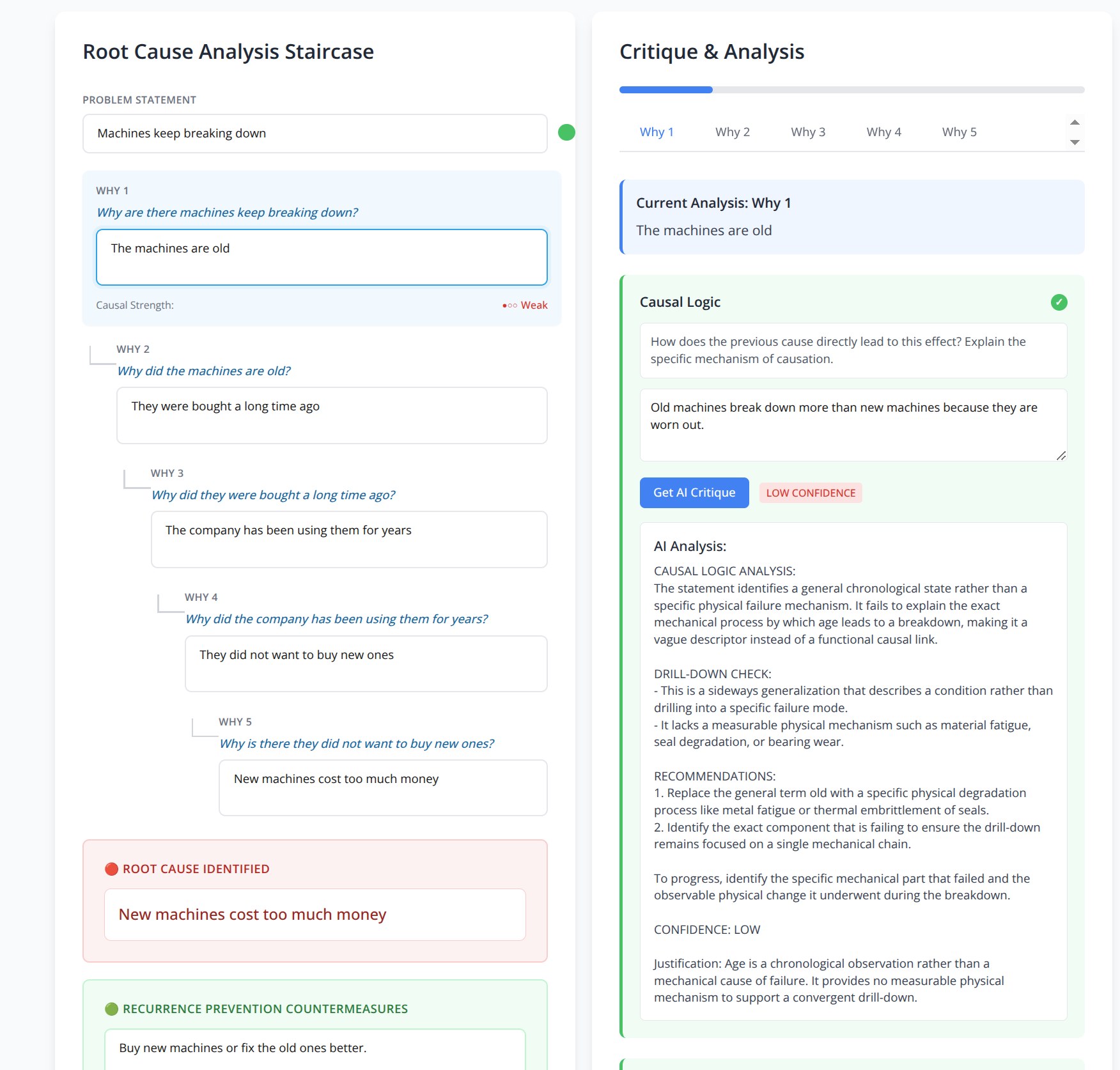
A deliberately weak 5 Why chain. This is useful as a beginner teaching example because RootCoach flags vague causal logic. It is not a strong demonstration of current model capability.
Why I Kept Going
Most people might have stopped there. I almost did.
But around the same time, I was consulting at a National Laboratory and could see serious people investing serious effort into artificial intelligence. That made me wonder whether I was testing the wrong thing, or testing it in the wrong way.
So I treated the AI’s weak 5 Why performance as its own root cause problem: why could the model not execute a disciplined 5 Why?
Public discussion of early system prompts helped explain part of the answer. I did not jailbreak models myself, but I read what others had shared. The model was being guided to be broadly helpful, exploratory, conversational, safe, and expansive. In many contexts that is useful. But it does not naturally align with a convergent 5 Why.
A 5 Why is supposed to narrow. The model wanted to explore. A good 5 Why drills down one causal pathway. The model wanted to branch. That was an important insight. The model was not simply “bad.” It was doing something different from what I wanted.
Reasoning Models Changed the Picture
Then the reasoning models started appearing.
By “reasoning model,” I mean the class of models that began explicitly spending more compute on multi-step reasoning before answering. OpenAI’s o1 series was one early public example. The marketing language around these models can be overdone, but the practical difference was noticeable: they were better at holding several facts in mind, checking intermediate logic, and noticing when a conclusion did not follow from the evidence.
The early versions were not perfect, but they behaved differently. They weighed facts more carefully, checked logic more explicitly, and were better at spotting gaps.
When I fed them old A3 reports and problem-solving examples, the results were no longer just funny. They caught weak causal links, noticed sideways jumps, and challenged vague answers like “lack of training” or “poor communication.”
The breakthrough for me was not simply “better prompting.” It was realizing that I should stop treating 5 Why analysis as a one-shot question. Each causal link could be checked separately against a standard. The model could critique, the user could revise, and the process could continue.
That led me to build a tool I first called AI-5Why, and later RootCoach.
RootCoach Is Not “AI Writes the Answer”
This distinction matters.
RootCoach is not designed to have AI magically produce a root cause answer for the user. That would be the wrong lesson.
The better use of AI is as a coach and checker. The user still owns the problem. The user still needs to go see the actual condition. The user still needs facts, measurements, and judgment. But the AI can help test the quality of the thinking.
In RootCoach, the visible part is a 5 Why staircase. The user enters the problem statement and then works down the causal chain step by step. But the real method is not the staircase alone.
At each step, RootCoach checks three things:
- Causal logic. Does this answer explain how the previous condition caused the effect? Is it drilling deeper into the same causal chain or branching sideways? Does it pass the “therefore” test?
- Evidence. What data, measurement, observation, or physical evidence supports this causal link? Is the evidence specific and relevant, or just anecdotal?
- Verification method. How would you test or disprove this causal relationship? What experiment, inspection, comparison, or control condition would confirm the mechanism?
That triple check is the important part.
The 5 Why technique is excellent, but it has a common weakness: you can fool yourself into thinking the logic looks right. A chain can read smoothly on paper and still be wrong. I learned this lesson at Toyota, especially working around the Kamigo engine plant, where dimensions are measured in microns — 0.001 millimeter. In that environment, you do not get very far with plausible verbal logic alone. You have to measure, confirm, and understand the reliability of the measurement method.
So the version of 5 Why I learned in practice was more scientific than the simple public version people often describe. We rarely treated it as just five verbal answers. For each leg of the causal chain, you had to ask: does the logic hold, what evidence or measurement supports it, and how would we verify or disprove it? I sometimes joke that I learned the 15 Why at Kamigo, not the 5 Why: logic, evidence, and verification for each step.
I am not saying every problem requires this level of rigor. A simple administrative problem may not need micron-level thinking. But when physical causation, quality, safety, or technical failure is involved, the extra discipline matters. It prevents the 5 Why from becoming a storytelling exercise.
When the reasoning-era models arrived, I found that I could program this discipline into RootCoach. Instead of asking the model to judge a whole 5 Why at once, I could have it test causal logic, evidence or measurement logic, and verification method separately. When I did that, the mistakes and hallucinations dropped sharply.
A weak example might say, “The machine broke down because it was old.” RootCoach should challenge that. Old compared to what? Which part failed? What physical degradation occurred? What evidence shows that mechanism? How reliable is the measurement? How would you distinguish that from lubrication failure, overload, contamination, misalignment, thermal expansion, or some other cause?
A Stronger Current-State Test
A stronger example looks different.
- Problem statement: Conveyor belt bearing seized, causing a four-hour production stoppage.
- Why 1: Bearing inner race developed a 0.3mm deep wear groove, causing lubricant film breakdown.
- Why 2: Metal particles in the lubricant acted as an abrasive compound between the race and rolling elements.
- Why 3: Lubricant filter bypass valve stuck open, allowing unfiltered oil to circulate.
- Why 4: Valve spring compressed beyond its elastic limit due to excessive pressure differential.
- Why 5: Filter element clogged, reducing flow area by 85 percent and creating a 45 PSI pressure drop.
Now the result is more promising.
Not because the example is more technical. Technical language can hide weak thinking just as easily as plain language can. The improvement is that the chain is more physical, measurable, and testable. It still needs checking. It also does not mean the true root cause has been fully identified. Ending at “filter element clogged” is not the final answer in a real investigation. A good problem solver would still ask why the filter clogged. Was there abnormal debris generation upstream? Was the filter interval wrong for the actual contamination load? Was there a damaged seal, poor cleaning practice, wrong lubricant, or another source of particles? The next level matters.
But that was not the main point of this test. I was testing whether the model could follow the thinking pattern: stay in the same causal chain, avoid jumping sideways, express physical mechanism, and ask for evidence and verification. Getting the model to reason reliably to this level is already useful. The next generation of models will likely go further with less scaffolding.
So the example is not presented as a perfect completed 5 Why. It is a stronger current-state test of the coaching logic. The chain is physical, measurable, and testable. The discussion can move from vague opinion to evidence.
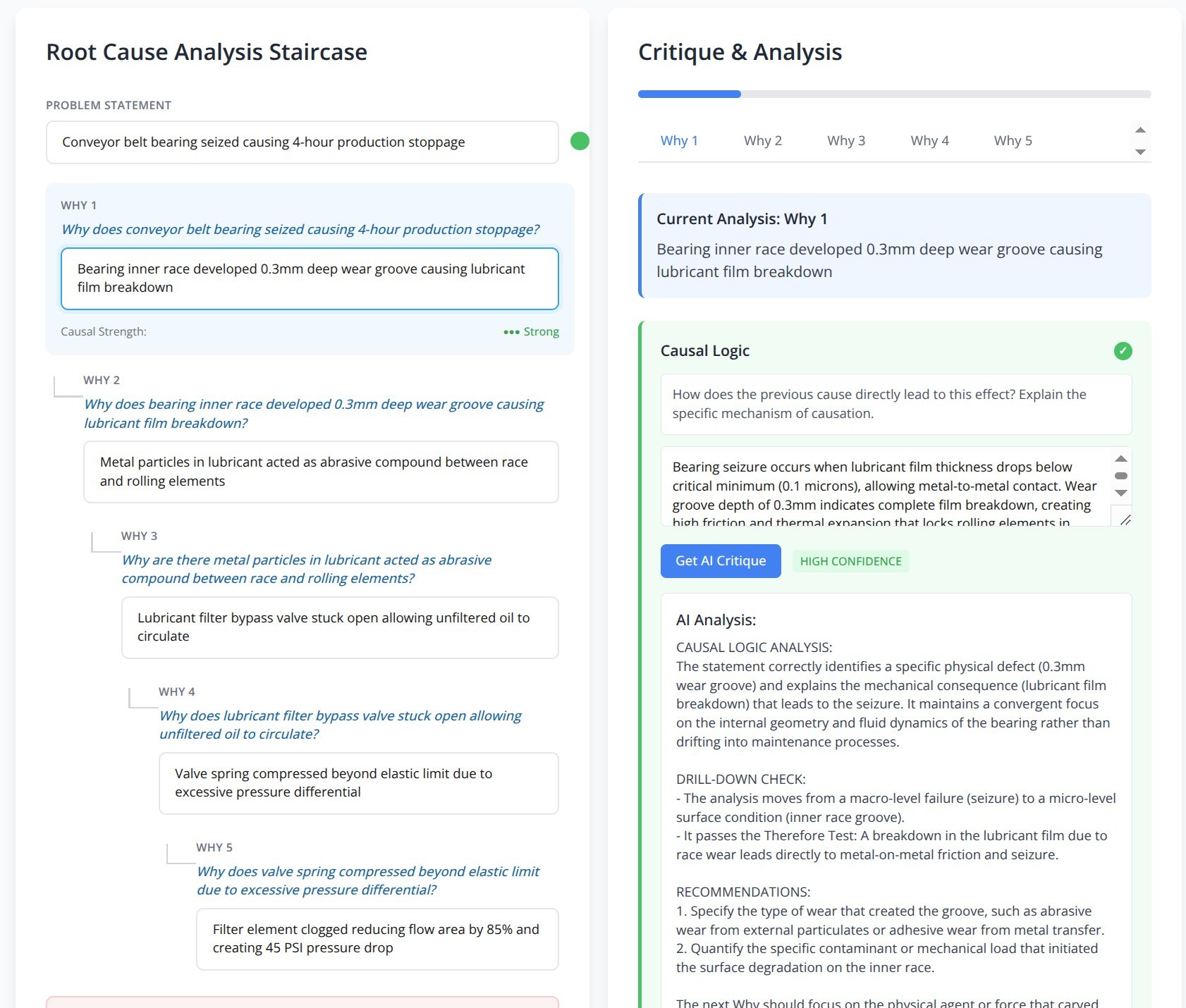
A stronger current-state test. The model is not just detecting a vague answer. It is evaluating physical mechanism, convergent drilling, measurable evidence, and what the next why should investigate.
One limitation of the screenshot is that it only shows part of the tool. The coaching responses are more important than the staircase itself. The staircase shows the user’s causal chain. The critique panel shows whether the model can evaluate the thinking: mechanism, evidence, and testability.
A Harder Test: A Strong A3 Example
Another test I like uses a problem-solving training example from Toshiko Narusawa’s Kaizen Express material, included here with permission. This is a strong teaching example by design: background, current state, target, observation, hypothesis, countermeasures, results, and next challenge.
That is exactly why I like using it as a test. Earlier models tended to praise it broadly and stop there. Current models, with the right coaching logic, recognize the strengths and then notice the intended teaching point: one branch stops a step short. The analysis identifies a small burr on the leaf spring as the source of straight scratches, but the deeper root-cause question remains: why was the burr present?
That is not a criticism of the example. It is the point of the example. The A3 itself even points toward this in the result and next challenge section: “Burr — why?” It is an excellent coaching setup because the learner has to see both things at once: the A3 is strong, and the thinking is still not finished.

A strong A3-style training example from Toshiko Narusawa’s Kaizen Express material, used with permission. The useful AI coaching behavior is not merely praising the example. It is recognizing the strength while also catching the intended next question: the burr was found, but why was the burr there?
That is the kind of feedback I want from an AI coaching tool. It does not dismiss the A3. It improves the learning conversation around it. A good human coach might catch the same point, of course. Fortunately, humans and AI have different strengths. If AI can give students faster, more consistent feedback while the human coach remains responsible for judgment and context, that is a useful development.
Where I Stand in May 2026
The latest generation of models changed my view again. The best models I am testing — examples such as ChatGPT 5.4, Claude Opus 4.7, and Gemini 3.1 — are much stronger than the early ChatGPT-style tools I first tested. Error rates are lower. Nuance is better. They catch weak reasoning more often and require less scaffolding.
The limiting factor has shifted. Early on, even a skilled user could get weak results because the model itself was not good enough at the task. Now, with stronger models, the problem is often the human method: how the problem is framed, what facts are provided, what standard is used, and how the output is checked.
That is why agentic programming mattered to me. I thought I was learning Python and TypeScript. In reality, I was learning a new way to structure work: break the task into steps, give the model tools and context, check outputs against standards, and iterate within boundaries.
That is close to good problem solving anyway. Define the problem. Understand the current condition. Ask the next question. Check the evidence. Verify the mechanism. Adjust based on what you learn.
AI should not replace going to the gemba, observation, measurement, experimentation, or responsibility. But dismissing it as a toy is now also wrong. Used properly, AI can challenge vague 5 Whys, ask for evidence, suggest verification methods, and help a coach review examples faster.
AI can provide another pass against a standard. Not the final pass. Another pass.
Six-Month Benchmark Notes
This field is moving faster than any book, article, or software application can fully capture. I am treating this post as a living benchmark.
| Period | Model era | 5 Why behavior observed | Typical errors | Scaffolding required | My conclusion at the time |
|---|---|---|---|---|---|
| Late 2022–2023 | ChatGPT / GPT-3.5 era | Could produce fluent 5 Why chains, but reasoning was shallow and inconsistent. | Jumped sideways, blamed training/procedures/culture, invented unverifiable causes, confused description with mechanism. | Heavy prompting, examples, repeated correction. Still inconsistent. | Useful toy, poor root-cause analyst. |
| 2023–2024 | GPT-4-class general models | Better language, better structure, somewhat better critique of weak logic. | Still accepted plausible but weak causal chains; sounded confident when facts were missing. | Strong prompts, rubrics, step-by-step constraints, human review. | Potentially useful as a coach if tightly constrained. |
| 2024–2025 | Early reasoning models / o1-style models | Began weighing facts and logic more explicitly. More likely to catch weak causal links. | Could over-reason from incomplete facts or create a tidy explanation beyond the evidence. | Moderate scaffolding: break the 5 Why into steps, check each link, require evidence and verification. | No longer funny. Useful with disciplined workflow. |
| 2025–May 2026 | Current frontier models: ChatGPT 5.4, Claude Opus 4.7, Gemini 3.1 | Much better at causal critique, evidence gaps, verification logic, and technical nuance. | Still dependent on problem framing and factual context. Can still hallucinate if starved of facts. | Less prompting needed, but structured workflow still improves reliability. | The bottleneck is increasingly the human method, not raw model capability. |
| Next update | Future GPT-6 / Opus 5 / Gemini 4 class models | To be tested. | To be tested. | Expected to need less custom prompting and programming, but still require standards and verification. | Update pending. |
Closing Thought
I started this journey trying to prove that AI could not do a 5 Why. For a while, I was right. Then the models improved. Then my method improved. Then the models improved again.
That is probably the main lesson. In a fast-moving field, yesterday’s conclusion may be correct and still become outdated.
Good problem solving still requires facts, logic, evidence, verification, and judgment. Used poorly, AI will produce confident nonsense faster than before. Used well, it can help expose weak thinking and strengthen the learning loop.
That is where I stand as of May 2026. Ask me again in six months.